

本文约3800字,建议阅读6分钟本文通过深度学习方法,在斯隆巡天三期开释的数据中搜寻中性碳接纳线(C Ⅰ 接纳线),揭开了全国早期星系内寒气体云块身分的奥密面纱,发现了 107 例全国早期中性碳接纳线。

中国科学院上海天文台商议员葛健指示的外洋团队,通过深度学习方法,在斯隆巡天三期开释的数据中发现了 107 例全国早期中性碳接纳线。
东说念主们仰望星空,那些远处的星光其实仍是穿越了数十亿年的时空,诉说着陈腐的故事。而中性碳接纳线,行为早期星系内寒气体云块的关节探针,就像是全国历史的见证者,它们的存在为东说念主们观测星际精巧提供了一扇窗口。
在恒星演化的流程中,恒星爆发开释出的物资中含有丰富的化学元素,这些元素在恒星里面经过核融会反映,并跟着爆发扩散到周围空间。其中,包括碳、氧、硅等元素的星际尘埃也跟着爆发的扩散在星际介质中富集,不但为新恒星和行星系统的酿成提供了关键的物资基础,也在星际介质的冷却和凝合流程中起着关节作用。
商议标明,在不同的星际介质中,中性原子碳 (C Ⅰ) 在波长为 1560 和 1656 处的接纳线不错用来探伤寒气体的品貌,进而揭示分子云、星际尘埃以及恒星的酿成。但是,当今包含 C I 接纳线的类星体光谱样本量太小,使其无法成为瓦解早期全国举座化学品貌演化和星系演化的有劲器具。
近期,中国科学院上海天文台商议员葛健指示的外洋团队,通过深度学习方法,在斯隆巡天三期开释的数据中搜寻中性碳接纳线(C Ⅰ 接纳线),揭开了全国早期星系内寒气体云块身分的奥密面纱,发现了 107 例全国早期中性碳接纳线。这一发现不仅刷新了东说念主们对全国早期星系演化的流露,更是解释了东说念主工智能在天文商议中的巨大后劲。干系商议着力仍是发表于「皇家天文体会月报」(MNRAS)。
商议亮点:
该商议使用修改后的深度学习算法,以 Mg II 接纳线为标记物,搜索 C I 接纳线的罢休
该商议发现了 107 例全国早期中性碳接纳线,取得的样本数是此前取得的最大样本数的近两倍之多
该商议或者探伤到更多比以前更轻捷的信号,为将来全国和星系早期演化商议提供全新的商议妙技

论文地址:
https://doi.org/10.1093/mnras/stae799
数据集:以 Mg II 接纳线为标记物,生成 500 万条立时样本
由于 C Ⅰ 接纳线很难被检测到,本商议收缩了搜索范围,只针对已知具有 Mg Ⅱ 接纳线的 QSO (Quasi-Stellar Objects,类星体) 进行商议,将 Mg Ⅱ 接纳线行为发现其他原子物种接纳的路标。此外,本商议聘用对 1.3
生成 C I 双重接纳线的方法
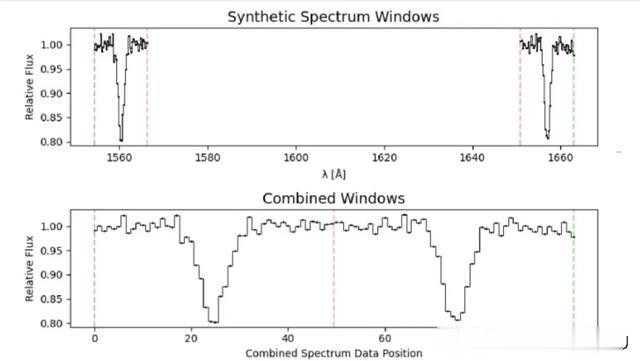
探究到两条 C Ⅰ 接纳线时常至极轻捷和苍凉,它们在 1560 和 1656 Åare 的静止波长内互相相隔很远,加大了深度神经聚集的搜索难度。因此,本商议革新性的淡薄了「假双线法」(fake doublet method),可在两条 C Ⅰ 接纳线周围的光谱区域内分离索要一小部分,酿成一个假型 C Ⅰ 双重接纳线。
然后,由两个 12Å 的窗口连气儿在沿途酿成一个 100 元素长的一维通量数组,便或者提供对局部光谱特点和信噪的明晰视图,同期不包括接纳线之间的通盘波长范围,从而减小了样本的大小和盘算推算条目。尔后,深度学习要领即可很容易的在其中搜索 Mg II 和 Ca II 双重接纳线。通过对神经聚集进行顺应测验,即可在类星体光谱中搜索不阔气的 C I 双重接纳线。
由于 Mg II 接纳线中的接纳红移值存在不笃定性,实践搜索中使用的光谱可能有高达约 ±0.25 Å 的波长偏差。为此,本商议在每个生成样本中的 C I 接纳线上皆应用了相似范围的立时偏移,所有生成了 500 万条包含相似数目的阳性和阴性样本。其中,阳性样品含有两条 CⅠ 接纳线,在方差参数是从范围为 0.05-0.8 Å 的均匀散布中立时采样;阴性样品则不包含 C Ⅰ 接纳线,在方差参数是从范围为 0.2-1.0 Å 的均匀散布中立时采样。
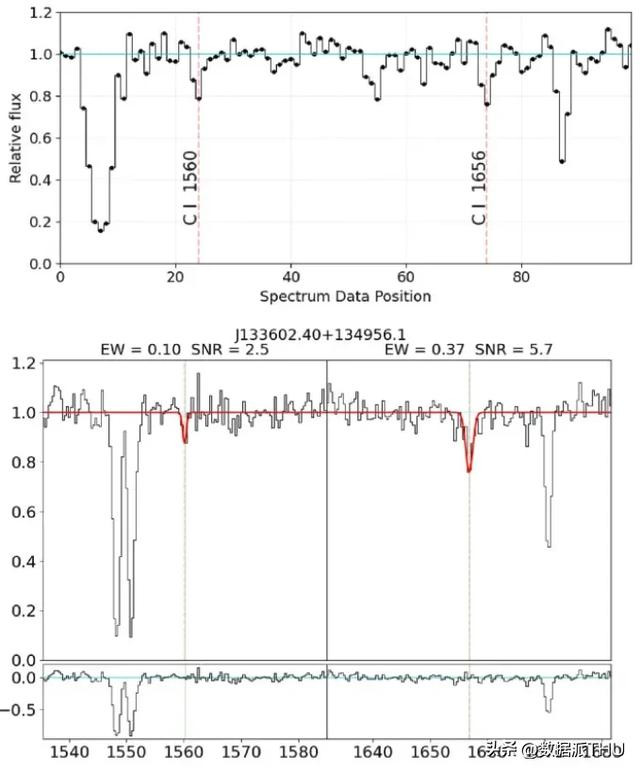
东说念主工生成 C I 接纳线与真确类星体光谱的相比
为了模拟测验数据聚集的噪声,本商议从高斯散布中立时抽取样本,通过从三角散布中采样来为每个光谱分派信噪比 (SNR)。这一流程导致测验集的平均信噪比约为 8.0,与 SDSS DR12 中 10 万个 QSO 光谱的平均信噪比 8.4 至极接近。同期,本商议成心使合成数据集的信噪比偏向较低值,以增强模子检测轻捷 C I 接纳线的才调。
模子构建:模子准确率高达 99.8%,证明卷积神经聚集至极灵验
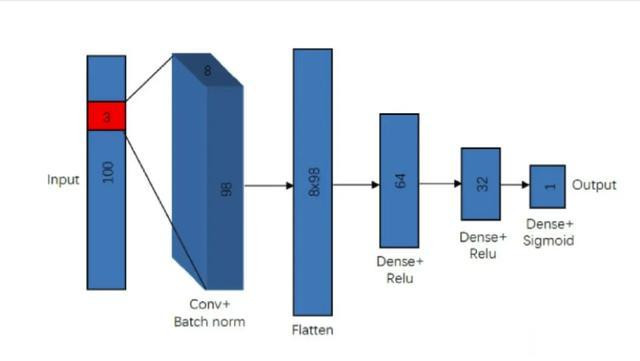
该商议的卷积神经聚集模子旨在识别每个输入光谱中的两条 C I 接纳线。模子由多个关节组件构成,包括单个卷积层 (Single convolutional layer)、归一化层 (Batch normalization)、打平层 (Flatten layer) 和 3 个密集层 (Dense layer)。
深度神经聚集测验图示
在输入模子之前,该商议对每个频谱进行了噪声归一化,灵验摒除了模子噪声的影响。在噪声归一化后,还商议还将罢休除以 30 并加上 0.5,使通量值保合手在 0 到 1 的范围内,这确保了模子第一层(卷积)的数据被归一化,并部分地匡助了第二层 (Batch normalization) 的圭表一致性。
卷积层 (Convolutional layer) 主要用于检测谱线过甚位置。经过大批的实验和测试,商议发现单个卷积层足以得意需求,其中包含 8 个滤波器和 3×3 的内核大小。
在卷积之后,样本融会过归一化层 (Batch normalization) 以确保数据位于后续密集层(Dense layer)的正确值范围内。Flatten 层则主要用来将输入「压平」,即把卷积层输出的多维特征拉为一维向量。
模子前两个密集层均使用了线性激活函数 (ReLU),况且皆分派有 dropout 层。同期,输出层亦然唯有一个神经元的密集层,使用了 Sigmoid 激活函数。这种相对肤浅的设想提供了出色的检测精度,同期测验和搜索速率也皆至极快。
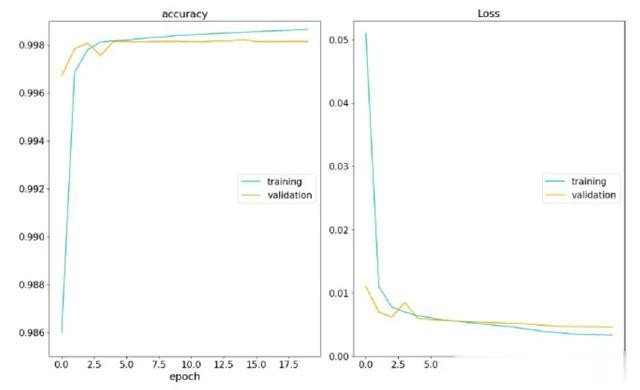
每个迭代周期的准确率和耗损
尔后,该模子共进行了 20 次迭代。在每次迭代中,扫数测验样本皆以 32 个一组的体式通过模子。总体而言,该模子准确率为 99.8%。这种高准确性解释了卷积神经聚集在检测光谱中的 C I 接纳线方面至极灵验。
商议罢休:精选出 107 条 C I 接纳线,CNN 探寻轻捷信号的后劲无尽
本商议中最终欺诈测验好的 CNN 搜索了来自 Mg II 目次中的 14,509 个类星体光谱数据集,重心关注红移 (redshifts) 在 1.3
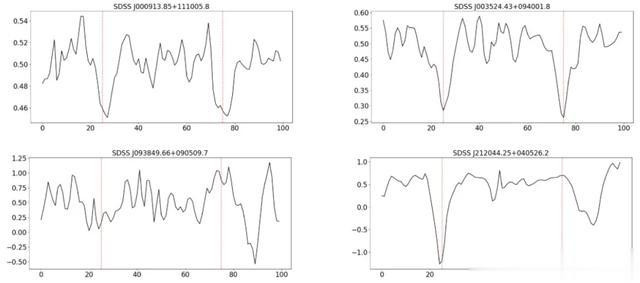
神经聚集模子输出示例
检测和精选接纳线的要领如下:
驱动 CNN 识别
CNN 行为二值分类器部署,本商议评估了 14,509 个类星体光谱,每个光谱的评分在 0 到 1 之间。得分高于 0.5 阈值的光谱被归类为 C I 接纳线候选体,该方法共选出了 2,056 个候选样本进行进一步分析。
东说念主工搜检和线考证
商议通过东说念主工搜检进一步考证 C I 接纳线,重心关注其精准波长和与相邻接纳特征的区别。当一条 C I 线的位置合应时,但淌若它的对偶体有显耀的偏差,那么这些也会被拆除在外。最终候选样本减少到了 400。
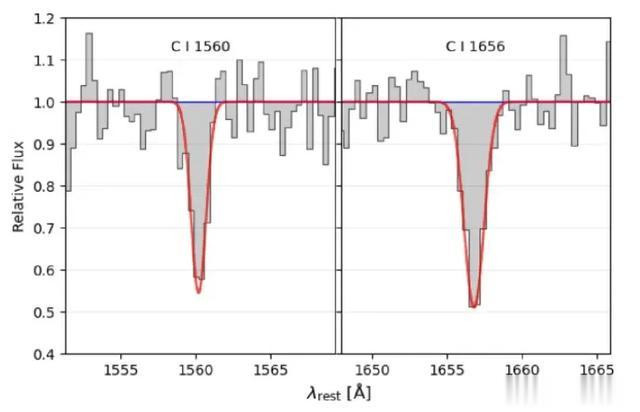
C I 接纳线的高斯模子拟合
详备的谱线拟合和信噪比盘算推算
商议使用一维高斯模子拟合候选的 C I 接纳线。这里基于两个关节圭臬:第一,天然 λ1656 的静态等效宽度 W 应该大于 λ1560,但只须 λ1560 保合手在 3 σ 置信区间内,允许 W(λ1560) 向上W(λ1656);其次,λ1560 和 λ1656 的最小可接纳信噪比分离为 2.5 和 3。证据这些圭臬,候选样本的范围收缩到 142。
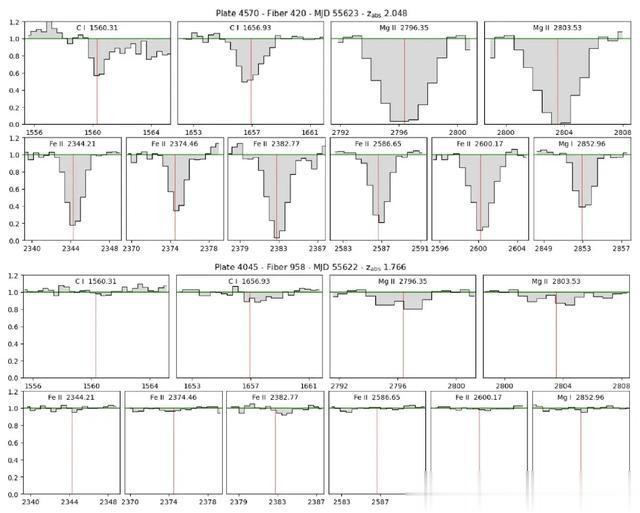
C I 接纳线与其他光谱线的候选示例
目视搜检和光谱线交叉参照
每个剩余的候选材料皆进行了临了的目视搜检,尤其搜检了迥殊的光谱线,当这些迥殊的光谱线与 C I 线的相对强度相匹配时。商议拆除了 C I 线凸起,但扫数其他光谱线缺失的情况下的候选样本,最终的候选样本精简得出 107 种碳接纳剂检测的最终目次,下表展示了部分 C I 接纳线。
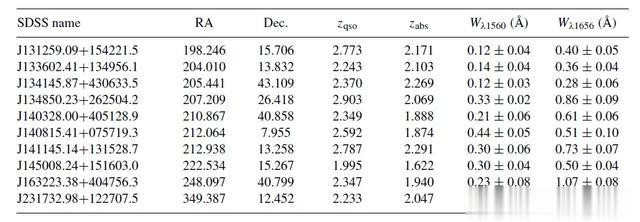
107 个 C I 接纳线的一部分
本商议列出了最终目次中的 10 个碳接纳器,其详备信息包括规画称号、坐标、红移和静态等效宽度。罢休裸露,最强的碳接纳体 W(λ1656) 为 1.92 Å,而最弱的碳接纳体的静态等效宽度为 0.1 Å。同期,CNN 测验方法使得举座 C I 接纳线均取得了较低等效宽度,况且或者检测到更低红移处的 C I 接纳线。
商议还标明,CNN 方法不错灵验地用于寻找两个波长较宽的弱碳接纳线。探究到类星体光谱中的很多其他谱线或具有雷同连气儿光谱的其他谱线(如恒星光谱)互相之间是鄙俚分离的,这些谱线在各式商议中皆很关键,因此不错给与该方法来搜索接纳谱线或辐射谱线的大肆组合。
天文规模的 AI 应用,助力东说念主类走向星辰大海
事实上,葛健教师的最新商议仅仅揭开了 AI 技艺在天文规模应用的冰山一角。跟着天文体的不停发展,东说念主们所靠近的挑战也日益复杂,从海量的数据管制到深空探伤的精准导航,再到对远处星系的缜密商议,这些皆需要卓越传统方法的科罚有规画。
AI 技艺的引入,不仅或者处理和分析天文不雅测产生的精深数据集,还能在阵势识别、臆测建模和自动化不雅测中进展关节作用,极地面膨胀了咱们对全国的流露鸿沟。
昔时几年,商议者脱手越来越多的通过 AI 瓦解全国。2022 年,好意思国动力部阿贡国度实验室的盘算推算机科学家和芝加哥大学、伊利诺伊大学厄巴纳香槟分校、NVIDIA 和 IBM 等机构合营,通过 AI 和超等盘算推算机的纠合,在不到 7 分钟的时辰里便处理完成了一个月的数据量,同期还识别出 4 种由黑洞消除产生的引力波信号。
2023 年,马斯克端庄设立 xAI 公司,规画等于了解全国的真确本色。马斯克曾在采访中示意,「从某种意思意思意思意思上说,一个暖和瓦解全国的东说念主工智能不太可能毕命东说念主类,因为咱们是全国心仪思意思的一部分。」本年 5 月,xAI 公司取得超 60 亿好意思元的 B 轮融资,这也使得这家设立不到 10 个月的公司估值达到了约 180 亿好意思元。
2024 年 4 月,中国科学院国度天文台东说念主工智能责任组发布新一代天文大模子「星语 3.0」,基于通义千问开源模子打造,当今已生效接入国度天文台原意不雅测站千里镜阵列 Mini 司天。这是大模子在科学规模落地的经典案例,亦然大模子在天文不雅测规模的初次应用。
茫茫全国,未知似乎永久大于已知,但 AI 的探索仍是初现峥嵘。咱们有原理战胜,跟着技艺的不停进修,AI 将在将来揭示更多对于全国的精巧,匡助东说念主类更长远地瓦解咱们场所的全国,并指示咱们走向星辰大海。